The content of this page has not been vetted since shifting away from MediaWiki. If you’d like to help, check out the how to help guide!
Introduction
While BigStitcher (using BigDataViewer) is great for displaying the alignment results and manually inspecting your data, subsequent processing steps by other ImageJ-plugins or different programms typically require “classical” (single) images (the aligned “image” that the BigDataViewer shows is calculated on-the-fly from the input images and not saved).
The process of creating single image stacks from multiple transformed/aligned input images is called Image Fusion. We offer two ways of creating fused images in BigStitcher and Multiview-Reconstruction:
Quick fusion
The quick fusion can be accessed by selecting Quick Display Transformed/Fused Image(s) from the main menu in both Stitching (under Fusion) and Multiview mode (under Displaying).
Selecting the menu item will open a sub-menu showing all Bounding Boxes as well as the fusion mode (Virtual, Cached or Precompute Image, see below for details).
The currently selected fusion mode is highlighted in red, clicking on another one will switch to that mode.
Finally, selecting a bounding box will open another sub-menu in which you can select the downsampling level to fuse. Click the desired level to fuse the image(s) and display the result in a new ImageJ-window.
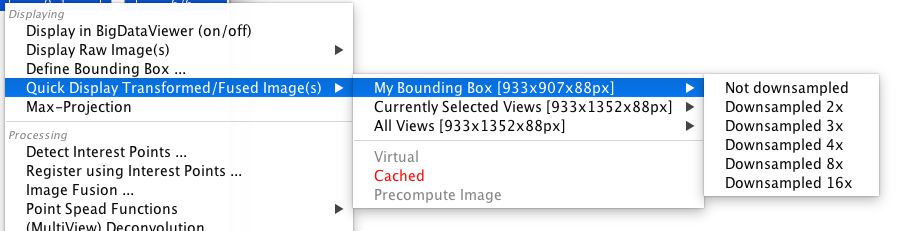
The quick fusion will fuse all selected images, including multiple channels/illuminations/time points, into one final image. To prevent e.g. a fusion of multiple channels, make sure to select only the images you need, ungrouping the views in the main window, if necessary.
Advanced Fusion
For advanced fusion options, select the desired views to be fused in the main window and click Image Fusion… in the right-click menu.
This will bring up a new dialog showing the fusion options:
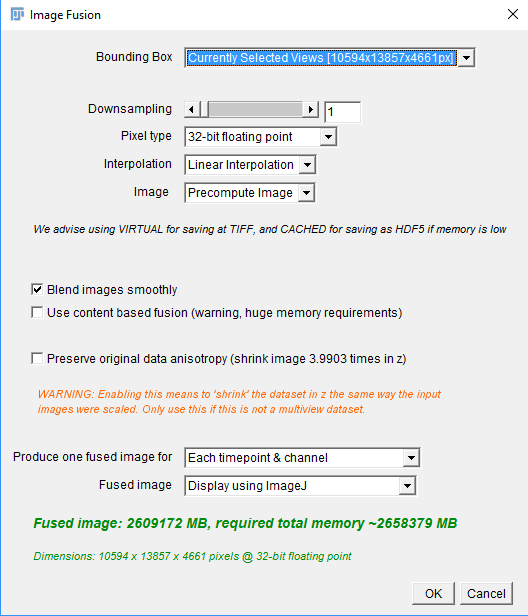
- Bounding Box: Here, you can select which sub-volume (Bounding Box) of the dataset to fuse. The options All Views and Currently Selected Views are always available, even if you did not manually specify a bounding box.
- Downsampling: The factor by which to downsample the image (in each dimension). Note that the resulting image will have the same pixel size in x,y and z, unless you choose to preserve original anisotropy (see below).
- Pixel Type: Whether to produce 16-bit unsigned integer or 32-bit floating point output. 32-bit results need twice as much disk/memory space but accurately represent the non-whole number results of the fusion. Selecting 16-bit output will round the output down to the next whole number (integer).
- Interpolation: Since the individual images were probably shifted to sub-pixel locations during the alignment process, we have to use interpolation to determine the intensity values at the pixels of the resulting image. You can choose whether to do Nearest Neighbour (faster, slightly “pixellated” results) or Linear Interpolation (smoother results, slightly slower).
- Image: How to create the resulting image in memory, can be:
- Virtual: Display or start saving the fused stacks immediately, calculating each plane on-the-fly. This way, you can fuse images larger than your computers RAM, but if you switch between planes, the calculation has to be repeated every time.
- Cached: like virtual, but keeping previously calculated planes in memory. The caching introduces a small computational overhead but for displaying, this is a good compromise between the unresponsive virtual mode and the memory-hungry pre-computed mode.
- Precompute Image: Calculate the whole fused stack before displaying or saving it. This might take a significant amount of time and have large memory requirements if you fuse large volumes, but the calculations have to be done only once.
- Blend images smoothly: The fusion process is a weighted average of the input images. Smooth blending causes less weight to be placed on border pixels of the input images (a cosine-shaped fade-out). If you deselect this, the fusion will simply average the images at each point, resulting in visible image borders in some cases (e.g. uneven illumination).
- Use content-based fusion: Select this to additionally weight the pixels to be averaged by the local entropy of the input images, giving greater importance to images with more structure/less blur. Use this to achieve better results in regions where some of the input images are blurred (e.g. because they were far from the objective). Because we have to calculate additional weight images for content-based fusion, this greatly increases memory requirements.
- Preserve original data anisotropy: By default, the fused image will have the same pixel distance in x,y and z. For non-multiview images (e.g. when stitching a “normal” tiled acquisition from one angle), this typically constitutes an unnecessary upsampling in z (if the original z pixel distance was larger than in x and y). By selecting this, we will use the original pixel sizes for the fused image. This option is not available when fusing multiple angles.
- Produce one fused image for: To no blend all the selected views into one image, the Fusion can fuse different subgroups of the selected views, with the options being:
- Each timepoint & channel: produce one output image for each timepoint and channel combination (fusing tiles, angles and illumination directions)
- Each timepoint, channel & illumination: produce one output image for each timepoint, channel and illumination direction combination (fusing tiles and angles)
- All views together: fuse all input views into one image. Take care not to select, e.g. multiple channels, in the main window as they will all be fused together (unless this is specifically what you want).
- Each view: produce one “fused” image for each input image. This will create an image of the bounding box with the view placed according to the transformations determined in the previous steps.
- Fused image: How to save or display the fused images. The options are:
- Display using ImageJ: Keep the results in memory and display them as “classical” ImageJ images. Use this if you want to immediately process the results further or save the in a different format using the export options of ImageJ.
- Save as (compressed) TIFF stacks: Save the results immediately to TIFF stacks. The resulting files will be put in the same directory as the current project XML file.
- Save as new XML project (TIFF): Save as TIFF stacks and also create a new XML project for them (useful if you want to visualize them again using BigDataViewer, but still need “simple TIFFs” for other processing steps).
- Save as new XML project (HDF5): Save the results to a multi-resolution HDF5 file and create a new XML project file for them.
- Append to current XML project (HDF5): Save the results to a multi-resolution HDF5 file and link them into the current project. Only works if the current project was already re-saved as HDF5.
At the bottom of the dialog, you will be presented with a preview of how big the resulting image will be and how much memory is needed for the fusion calculations.
Finally, click OK to start the fusion process.
If you chose to save the result as a new project, you will be asked where to save the .xml project file and the TIFF/HDF5 files for the fused views in a new dialog.
Furthermore, if you chose to save to the current or a new project as HDF5, you will be asked for options on how to save to HDF5.
Go back to the main page