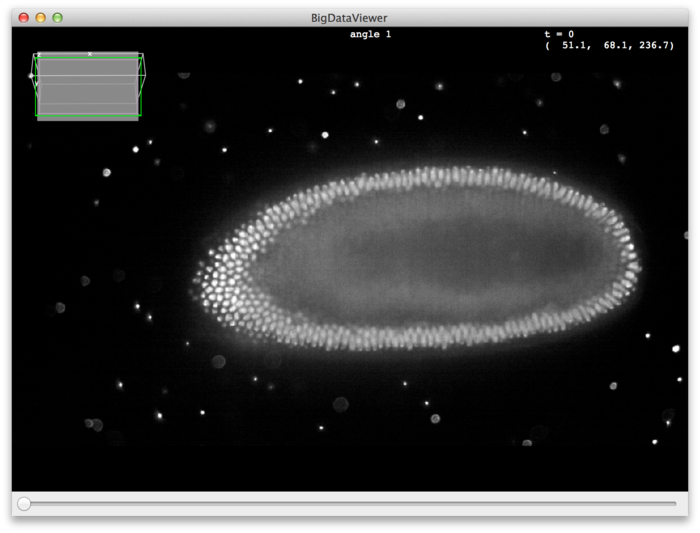
Description
BigDataServer is a minimalistic HTTP server that serves XML/HDF5 datasets to the BigDataViewer Fiji plugin for visualisation.
The BigDataServer is running on a remote machine which hosts the XML/HDF5 datasets. A client running Fiji connects to the server, chooses the dataset that the server offers and then the data are efficiently delivered to the BigDataViewer. In this way, it is possible to seamlessly navigate very large datasets that reside in a remote location.
Installing and running the BigDataServer
BigDataServer is packaged as a single “batteries-included” jar file with all required dependencies. It is run from the command line using Java 7 or higher. Copy bigdataserver.jar onto your webserver (probably running Linux). Run the BigDataServer using this command:
$ java -Xmx4G -jar bigdataserver.jar PARAMETERS
The -Xmx4G option gives the server 4GB of RAM. The server is built on the same caching architecture as BigDataViewer and does not require a lot of RAM to run (1GB or less should be sufficient). However, running with more RAM means that more of the data can be cached in RAM (on the server). This will improve performance, because client requests can be handled rapidly from cached data.
Running the above command without parameters will print this help:
$ java -Xmx4G -jar bigdataserver.jar
usage: BigDataServer [OPTIONS] [NAME XML] ...
Serves one or more XML/HDF5 datasets for remote access over HTTP.
Provide (NAME XML) pairs on the command line or in a dataset file, where
NAME is the name under which the dataset should be made accessible and XML
is the path to the XML file of the dataset.
-d <FILE> Dataset file: A plain text file specifying one dataset
per line. Each line is formatted as "NAME `<TAB>` XML".
-p <PORT> Listening port.
(default: 8080)
-s <HOSTNAME> Hostname of the server.
(default: localhost)
-t <DIRECTORY> Directory to store thumbnails. (new temporary directory
by default.)
A typical command to start the server will look like this:
$ java -Xmx4G -jar bigdataserver.jar -d datasets.txt -s fly.mpi-cbg.de -p 8081
2015-02-14 14:02:52.696:[INFO::main](INFO__main): Logging initialized @421ms
...
2015-02-14 14:03:12.316:[INFO:oejs.Server:main](INFO_oejs.Server_main): Started @20046ms
where dataset.txt is a TAB delimited list of names and XML paths to the locally accessible datasets (comprising the XML and HDF5 files). For example dataset.txt could look like this:
drosophila_original_test /mnt/export/hdf5_dataset.xml
drosophila_registered_test /mnt/export/registered_dataset.xml
The server will keep running until you cancel it with ⌃ Ctrl + C or close the shell. To start the server in the background run it in a screen session:
$ screen
$ java -Xmx4G -jar bigdataserver.jar -d datasets.txt
2015-02-14 14:02:52.696:`[`INFO::main`](INFO__main)`: Logging initialized @421ms
...
2015-02-14 14:03:12.316:[INFO:oejs.Server:main](INFO_oejs.Server_main): Started @20046ms
and detach the screen with ⌃ Ctrl + A D.
To add new datasets edit the dataset.txt and add new XML paths. After that you have to currently restart the server. (Re-attach the screen session with screen -r, cancel the server with ⌃ Ctrl + C and repeat the above).
Note that the server port needs to be open.
Connecting to a running BigDataServer from Fiji
In order to connect to a BigDataServer from Fiji and view the data go to Plugins › BigDataViewer › Browse BigDataServer. You will be presented with the following dialog box:
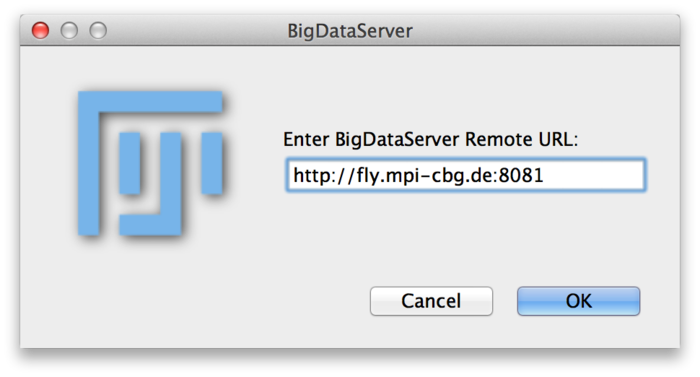
Enter the URL (including port) of a BigDataServer. For example, the Drosophila timelapse dataset described in BigDataViewer_Example_Datasets#Remote_HDF5 is available through this address: http://fly.mpi-cbg.de:8081. Click OK. The following window will pop up showing a list of datasets offered by the server:
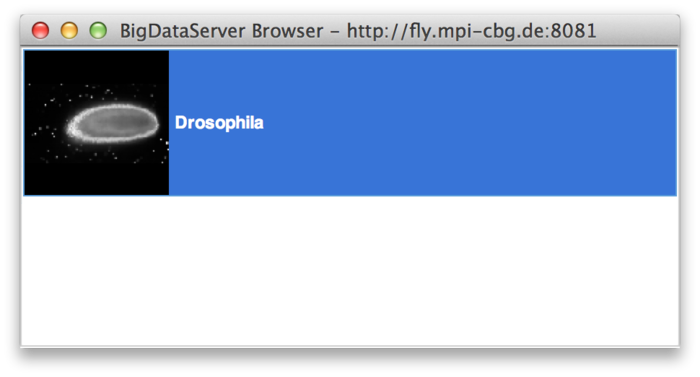
In the example, the server offers only a single dataset called Drosophila. Double-clicking on a dataset in the list will launch it in the BigDataViewer.